Who Reads My RSS Feed?
• ~4,000 words • 20 minute read
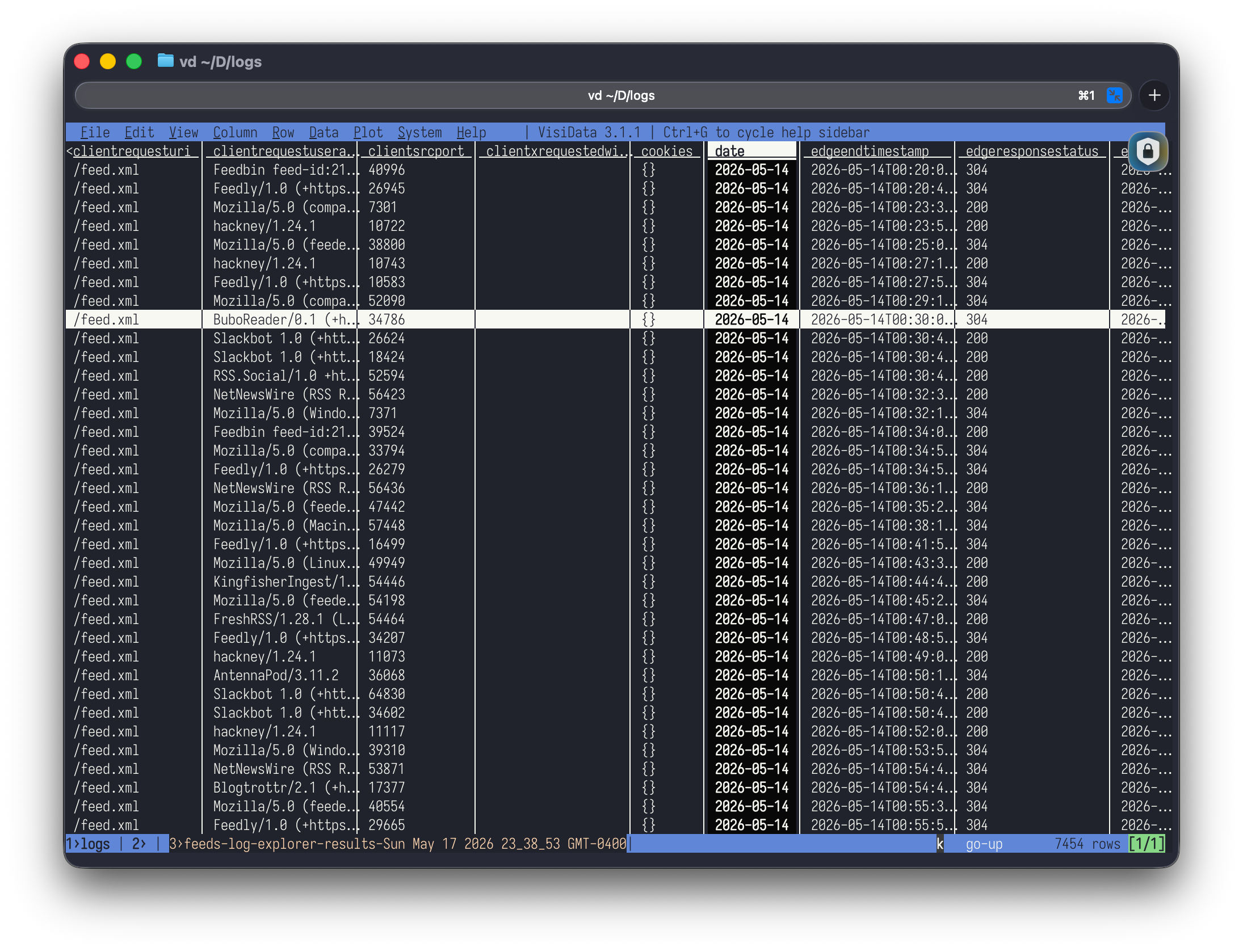
I recently moved my site from Netlify to Cloudflare Pages, partly to consolidate the services I'm using and partly to finally have proper server logs. Plausible is great for getting the gist of who's visiting and where they're coming from, but sometimes I'm curious about things like:
- Who is actually using my RSS feeds?
- What weird bots are sniffing around?
- Which home-rolled projects are people running against my site?
I have an RSS feed, a JSON feed, and an experimental plain-text feed. I wanted to see who or what was actually pinging them.
I've been able to collect these logs for about a week now—a week that happened to include one of my posts hitting the front page of Hacker News. This was great timing! Hacker News is good for bursts of interesting traffic to explore.
Across all feeds and the broader site logs I found over 700 unique user agent strings representing tens of thousands of requests. Some were familiar names to me, many were not. A few were genuinely bizarre. Here's a tour of the ones that caught my attention from the feed logs, plus a few highlights from the wider site traffic.
Note: this turned out to be a long write-up with a ton of links. There's a CSV at the bottom if all you want is to joylelssly ingest a list of user-agents with references. To each their own!
Readers
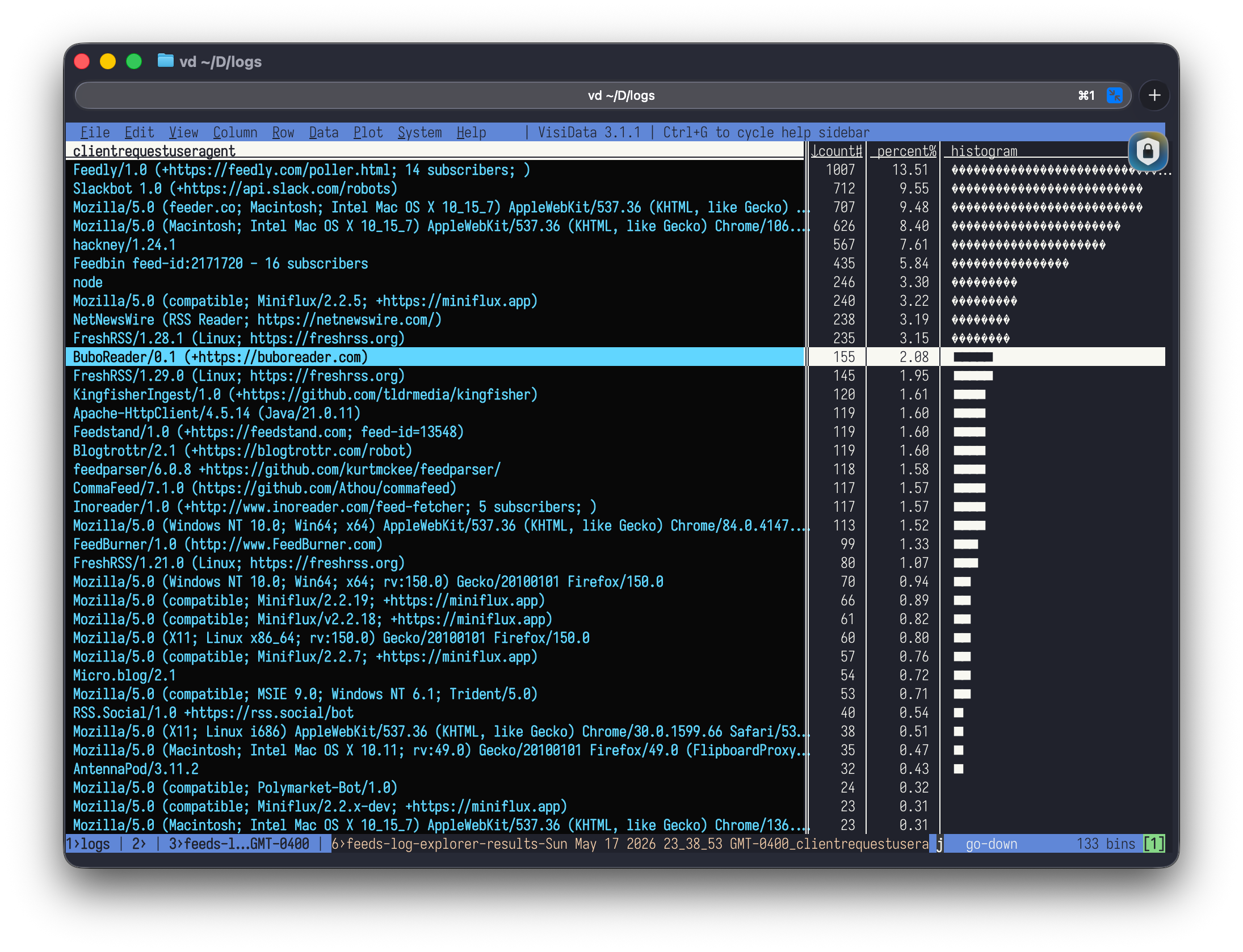
The core of the traffic is what you'd hope to see: people reading RSS with dedicated feed readers. But the variety is striking. There is a lot of homogeneity in the web browsing world, but the diversity in the feed reader space seems surprisingly strong. I have a hunch this is because the reader space is already quite niche, but it's also pretty easy to roll your own reader compared to your own browser.
I counted over 20 distinct reader products, and a significant self-hosted contingent.
Big hosted services I've heard of were all present: Feedly, Feedbin, Inoreader, and Feeder. Several of them helpfully report subscriber counts right in their user agent strings. Feedbin told me I have 16 subscribers! Feedly reported 14 on my RSS feed and 3 on my JSON feed. Inoreader said 5. That's a nice touch I didn't know about or expect. A small bit of transparency in an exchange that otherwise gives publishers almost no feedback.
The self-hosted readers were the really fun ones. Miniflux appeared in nine different version strings, which I think means at least nine separate installations are polling my feed. That's nine people running their own Go-based feed reader on their own servers. FreshRSS showed up with four versions. CommaFeed, the Java-based Google Reader replacement, was there. So was Bubo Reader, an "irrationally minimal" reader that generates a static HTML page from your feed list—no account, no descriptions, no server-side state—just a webpage full of links. Full disclosure: Bubo Reader is my project. It's open-source and my blog is in the default feed list, so I suspect some of these hits are people who forked the repo, deployed their own instance, and never removed my blog from the defaults. I thank you all for your patronage 🫡.
Native apps are still out there too. NetNewsWire, the long-running open-source Mac/iOS reader originally by Brent Simmons, had a strong showing. Unread was a new one to me and completely dominated my JSON feed, accounting for over 40% of all JSON feed traffic (the JSON feed generally is much lower traffic than my traditional RSS feed). It barely appeared in the RSS logs at all. feeeed, an iOS app by Nate Parrott that mixes RSS with Reddit, YouTube, weather, and step counts into a single scroll, showed up too. And AntennaPod, an open-source Android podcast app, was polling my blog feed. Someone has apparently subscribed to my blog as if it were a podcast? Please leave 5 stars.
On Android, ReadYou (an open-source Material Design reader) appeared in the wider site logs alongside the charmingly named SpaceCowboys Android RSS Reader. BazQux checked in with exactly 1 subscriber. GoodLinks, a reading-list app for Apple platforms, showed up too. And ReaderDesktop, a native macOS reader, made a single appearance.
The terminal readers represent a particular type of person—people after my own heart (I'm actually considering taking Bubo this direction). Newsboat was there, a terminal-based reader popular with the CLI crowd, but the one that really got me was Elfeed—Emacs Elfeed 3.4.2. Someone is reading my blog inside Emacs. Christopher Wellons' tag-based feed reader with Org-mode integration.
And then there's Syndicator, a personalized reading app that learns from your behavior and aggregates blogs, news, YouTube, and Substacks. It accounted for 37% of my JSON feed traffic. Between Unread and Syndicator, two apps I'd never heard of make up nearly 80% of all JSON feed requests.
The Fediverse
Multiple Fediverse platforms showed up in the logs. At least five different Misskey instances and six different Friendica instances were fetching my content—I won't link to any of them individually, but the pattern is clear: when someone shares a link on a Fediverse instance, the server fetches it for link preview generation. Tools like rsskey can also mirror an RSS feed directly into the Fediverse as posts, which might explain some of the traffic.
Micro.blog, Manton Reece's indie microblogging platform, was crawling too. As was Flipboard, fetching content for its magazine-style card previews.
Indie search engines
This category might've been the most interesting to me.
Marginalia Search (search.marginalia.nu) is a one-person search engine built by Viktor Lofgren that deliberately indexes the small, personal, non-commercial web. It deprioritizes SEO-optimized content and elevates human-scale sites. The whole thing is open source and designed to run on affordable hardware. Being crawled by Marginalia feels like a compliment.
Kagi (kagibot) was there too! It's a paid, ad-free, privacy-focused search engine that I've written about before. Kagi has a clever policy: if your robots.txt doesn't mention kagibot specifically but does have rules for Googlebot, it follows the Googlebot rules as a fallback. Unclear if their Orion browser was part of the traffic since it tries to obfuscate by design.
rssanyway (v0.1—very early) is a new service by Ryan X. Charles that generates RSS feeds for sites that don't have them and ranks trending content across all feeds in its index. It's bootstrapped from Hacker News and any URL that reaches some threshold of popularity gets added.
And GeistHaus is building an RSS meta-layer that ranks articles by how many feeds link to them—a kind of Techmeme built entirely on RSS data, with echoes of PageRank to my ears.
In the wider site logs, Smallwebindexbot appeared—yet another indie search engine specifically for the small web. rawweb-bot is a search engine for independent personal websites and blogs, built by someone who misses "the golden age of the internet when people thought, wrote, and shared on their personal websites and blogs." And YandoriRSSBot, built by a developer called antiochIst, monitors around 200,000 RSS feeds in near real-time and clusters related articles to track how stories spread across the web.
HN-serendipity-research/1.0 identifies itself as being from news.ycombinator.com—a research bot exploring serendipitous content discovery across Hacker News links. Whatever "serendipitous content" means, exactly.
The AI Crawlers
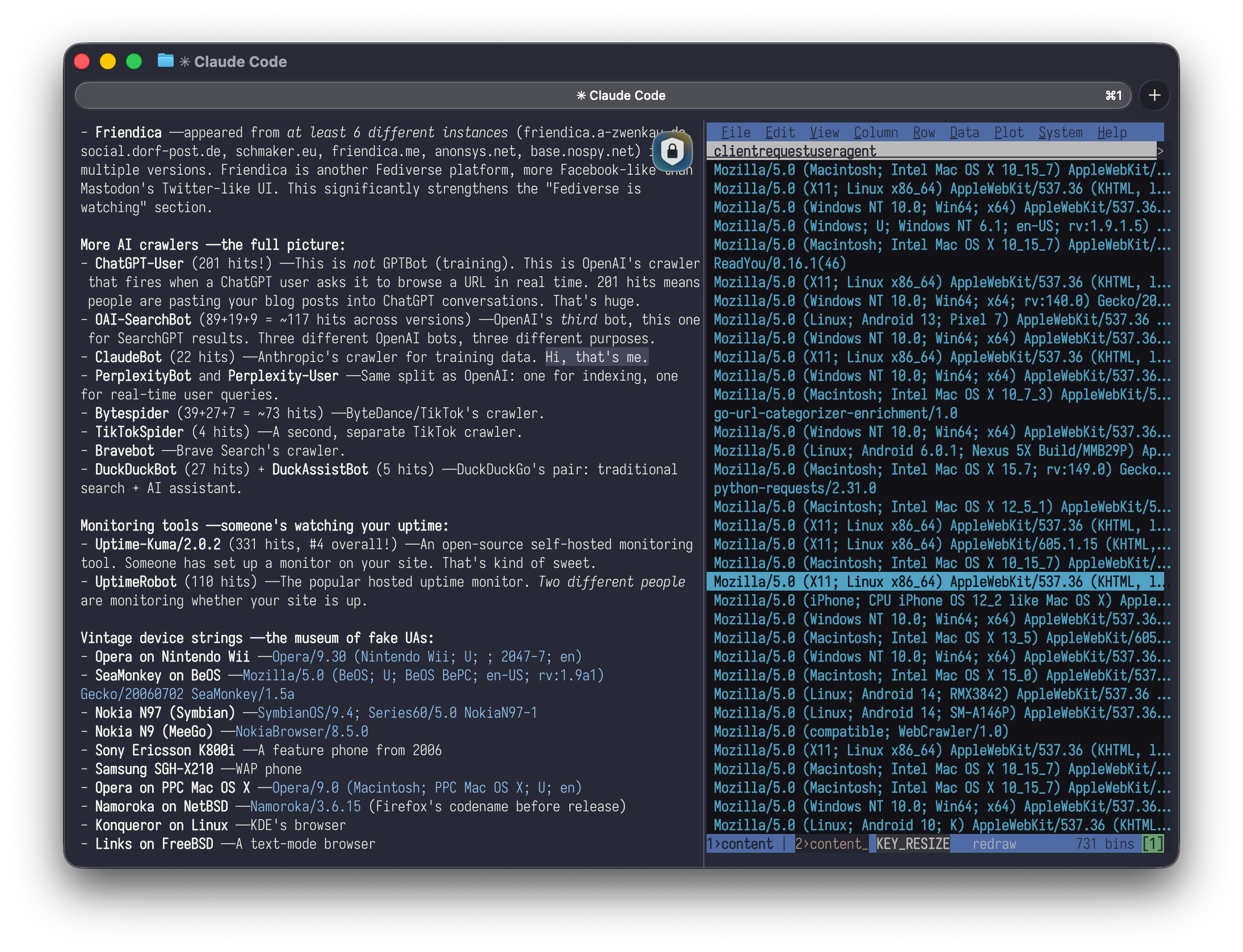
Unsurprisingly, the AI companies have arrived, and they are harvesting your tokens reading your feeds. The feed logs alone only showed a handful, but the full site logs revealed the true scale: AI crawlers are now one of the dominant traffic categories.
OpenAI alone sent three different bots which I learned more about in the course of researching and writing this:
- GPTBot is their training data crawler. It's also one of the most-blocked bots on the web.
- OAI-SearchBot powers SearchGPT results. I'm not sure, but I wonder if this is the agent you'll see when a model with web search capabilities checks out your site.
- And ChatGPT-User is the one that fires when a ChatGPT user asks it to browse a specific URL. That last one showed over 200 hits in the full site logs—though that number is probably misleading. A single "go read my blog" prompt can send ChatGPT on a crawling spree across multiple pages, so this doesn't mean 200 people pasted my URL—some of those hits are definitely me, when I asked it to go read my site and find themes.
Applebot was there, powering Siri, Spotlight, and Apple Intelligence. Amazonbot too, feeding Alexa's answers and the Rufus AI shopping assistant. ClaudeBot (Anthropic) showed up. PerplexityBot and Perplexity-User (the same training/real-time split as OpenAI). Bytespider (ByteDance/TikTok) was one of the noisier ones, with a separate TikTokSpider for good measure. Bravebot for Brave Search. DuckDuckBot for traditional search and DuckAssistBot for DuckDuckGo's AI assistant features.
Beyond the big names, there's a newer class of AI-native crawlers. AIWebIndex (from a company called Lyrenth) implements an open standard for AI-readable web crawling, converting URLs to structured JSON optimized for AI consumption. Their bot info page says "You probably landed here from a server log." Accurate! LinkupBot (from linkup.so) is building a search API for RAG applications, the kind of thing you'd plug into an AI agent that needs to search the web. And sauce.ai-news/1.0 (+discovery) appeared once with no documentation, no website, nothing. Just a name and the word "discovery."
Prediction markets (!!)
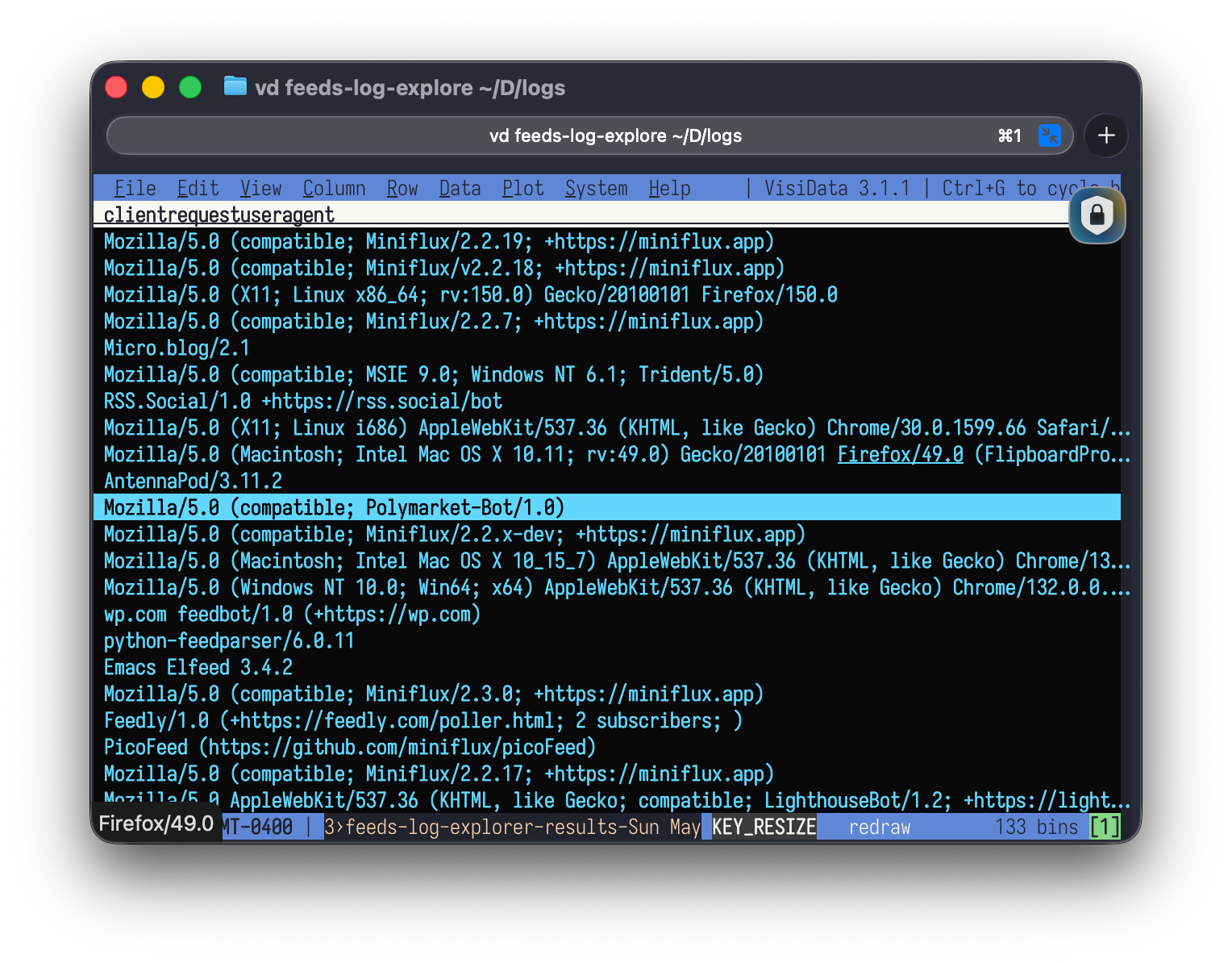
Okay, this one got me thinking.
Polymarket-Bot/1.0—as in Polymarket, the cryptocurrency prediction market—made 24 requests to my RSS feed. Not other pages, curiously—just the feed. I know prediction market bots scrape news sources to detect events that could move markets. My blog, apparently, is in their index of potential signal sources.
God, I hope writing about PaTUI shook markets.
This sent me down a brief daydream about a world where a bunch of us coordinate to publish increasingly unhinged content in our RSS feeds specifically to confuse Polymarket's bots. A sort-of distributed attack on prediction markets via RSS feed poisoning?
Maybe skim the latest markets and use a little LLM magic to conjure believably ridiculous stories that might drive things in a direction where they lose the most money? "Elon considers buying the moon." Maybe that's not unhinged enough.
Note: if you are noticing Polymarket sniffing around your blog and have similar aspirations, get in touch! I love a good scheme.
Preservation Layer
archive.org_bot—the Internet Archive's Wayback Machine crawler—appeared in the logs. My posts are being archived for posterity. I can still find websites I made in high school (!!) on there. Like an old friend you are always happy to see.
Shiori showed up twice, in two different versions. It's a self-hosted bookmark manager written in Go, an open-source alternative to Pocket. Someone bookmarked something from my site and Shiori fetched it to create an offline archive.
And someone is monitoring whether my site stays up. Uptime-Kuma, an open-source self-hosted monitoring tool, was the fourth most active agent in the entire site logs. Okay, one of those is me—but the other might not be! Someone out there cares enough about my uptime to run a health check against it.
Pipelines to email, Slack and newsletters
RSS isn't just about reading. It's also about syndication. It's piped. A significant chunk of traffic came from services that take feed content and push it somewhere else.
Slackbot was the second most active agent overall. This is just Slack's link unfurling, not a subscriber. Every time someone pastes a post URL in a Slack workspace, Slackbot fetches it to generate a preview card. Hundreds of hits in a week means people are actively sharing my posts in Slack conversations. That's arguably more interesting signal than subscription counts and pings, since a human may very well have had to actively share it!
Blogtrottr delivers RSS to email inboxes. Someone is getting my posts as emails. FeedBurner is somehow still alive, the Google-acquired feed proxy from 2007 that Google has been threatening to kill for a decade. If it's hitting my feed, someone still has a FeedBurner URL pointed at me from the old days. WordPress.com's Feedbot powers the WordPress.com Reader. Kingfisher is the ingestion bot for the TLDR Newsletter. Cool!
Runtime fingerprints
Some of the most interesting user agent strings are the ones that (presumably) reveal what someone's homebrewed script is written in.
Hackney, an Elixir/Erlang HTTP client, was one of the most active agents overall. Some Elixir application is very interested in my feed and I have no idea what it is. Apache HttpClient reveals a Java application. The bare string node—just "node," nothing else—means someone's Node.js script didn't bother setting a custom user agent. undici is what you get when you use fetch() in Node.js 18+ without customizing headers—it's the name of the HTTP client library that powers Node's native fetch implementation. Deno/2.7.5 means someone wrote a Deno script—created by Ryan Dahl, the same person who created Node.js. Bun/1.3.14 rounds out the JavaScript runtime trifecta on the JSON feed side.
SimplePie is the PHP feed parsing library that powers WordPress's RSS widget—so a WordPress site somewhere has my feed in a sidebar widget. feedparser and newspaper are Python libraries for parsing feeds and extracting article content respectively. feed2exec is a Python CLI tool that runs arbitrary commands when new feed items appear—someone has a little pipeline that triggers something every time I post.
The wider site logs add more to the collection. python-requests appeared in at least four different versions—the most common Python HTTP library, each version probably a different script or project. trafilatura, a Python library specifically designed for web text extraction and corpus building, showed up with notable volume. colly, a popular Go scraping framework. axios, the ubiquitous, and now infamously supply-chain-attacked, JavaScript HTTP client. And one of my favorites: gen_candidates.py (tech-news-daily)—someone left their literal Python filename as the user agent. A tech news aggregation pipeline, running a script called gen_candidates.py, apparently evaluating my blog for inclusion. Hey, it is an honor to be nominated.
And then there's Embarcadero URI Client/1.0. This is the default HTTP user agent from Embarcadero RAD Studio—the Delphi IDE. Someone built a Delphi application that fetches my feed. In 2026. Or at least, something out there is pretending to do that. It appeared in both my RSS and JSON feed logs. Respect.
Lies, damn lies and browser strings
A good chunk of the logs are standard browser user agent strings. A few might be real humans who opened the feed URL in a browser tab, but most are certainly not.
Chrome 84 from 2020. Chrome 30 from 2013. Internet Explorer 9 from 2011. IE 6 on Windows 2000. And my personal favorite from the JSON feed: someone claiming to be Firefox 35 on Windows 98. I'm not sure Windows 98 could run Firefox 35 even when Firefox 35 was current in 2015, let alone in 2026.
The wider site logs turn this into a full museum. Highlights from the collection:
- Opera on a Nintendo Wii—
Opera/9.30 (Nintendo Wii; U; ; 2047-7; en). The Wii's Opera-based Internet Channel, vintage 2007. - SeaMonkey on BeOS—
Mozilla/5.0 (BeOS; U; BeOS BePC)... SeaMonkey/1.5a. BeOS hasn't been a going concern since 2001. - Nokia N97 on Symbian—
SymbianOS/9.4; Series60/5.0 NokiaN97-1. The last gasp of Nokia's pre-Windows Phone era. - Nokia N9 on MeeGo—
NokiaBrowser/8.5.0. Nokia's beautiful, doomed Linux phone from 2011. - Sony Ericsson K800i—A feature phone from 2006, identifying via WAP headers.
- Konqueror on Linux—KDE's browser. Technically still maintained, but not commonly seen in the wild.
- Links on FreeBSD—
Links (2.1pre15; FreeBSD 5.3-RELEASE i386; 196x84). A text-mode browser at 196x84 character resolution. - Namoroka on NetBSD—
Namoroka/3.6.15. This was Firefox's internal codename before it was released as Firefox 3.6. - AOL Browser—
AOLBUILD/11.0.1839. Yes, really. - Opera on PPC Mac—
Opera/9.0 (Macintosh; PPC Mac OS X; U; en). PowerPC Macs haven't been manufactured since 2006.
These are bots or scrapers doing browser cosplay from years they weren't even plausible. This really underscores how user agent strings are a loose social contract and always have been—but these aren't even trying.
I look forward to updating my user agent string to let sites know I'm running Lynx on my Atari 2600.
SEO crawlers and international search engines
The SEO usual suspects were all present: AhrefsBot (one of the most active crawlers on the web), MJ12bot (Majestic SEO, doing backlink analysis since 2004), DataForSeoBot, and SemrushBot in multiple flavors.
More interesting was the international search engine contingent. PetalBot (Huawei's search crawler for Petal Search) was among the more active crawlers overall. Sogou (Chinese search engine—more info?), Baiduspider (Baidu), CocCocBot (Vietnamese search engine for Coc Coc—more info?), YandexBot (Russian search), SeznamBot (Czech search engine Seznam.cz), Yeti/Naver (Korean search for Naver), and Qwantbot (French privacy-focused search). My little personal blog, being indexed for search engines in at least eight countries. The web really is worldwide, even if that's easy to forget.
Xobaque also showed up. It seems like a delightfully personal project from Alex Schroeder trying to create an opt-in search engine.
As a fun aside: I used AI to give a first pass at the logs and help me research the different user agents and provide links so I could learn more about them. Then I went through all of the links to see what they were about. With this one it said "No web presence, no documentation, no results for the name anywhere. A ghost." I did a search in GitHub and found one reference on this AntennaApp issue which led me to Alex's blog, where I promptly asked to confirm my humanity. I guess it's working, since AI couldn't find it?
Also lurking in the wider logs: something called go_revenue_model, presumably a Go tool by Florin Badita that apparently analyzes website revenue models, made 33 requests. The GitHub repo seems to be private, so I can't tell you much more about it.
Maybe someone is studying how I make money from this blog? Spoiler: I don't. Unless you'd like to sponsor me.
The Mysteries
We are hitting the long-tail of user agents and trodding firmly in the Low Information Zone (Yes, I'm outing my hobby of reading about debunking conspiracy theories on sites like Metabunk and Skeptoid). Here are some weird ones:
- bushbaby/2026.5.1—This one looked weird. Turns out it's a Cloudflare internal bot used for SSL certificate renewal checks.
- ED309134-1C93-41BB-A10D-3278DF6BCF72/310—An iOS app that forgot to set its display name in the app bundle! It shows up as a raw UUID. The
CFNetwork/Darwinsuffix confirms it's a native iOS app. Someone's homebrew feed reader, still in development, already subscribed to my blog? Charmed. I hope they ship it. - br-crawler/0.5—Listed in bot directories but categorized as "uncategorized." I couldn't find anything.
- Thinkbot/0.5.8—Gets honorable mention for the most polite user agent string I've ever seen:
"In_the_test_phase,_if_the_Thinkbot_brings_you_trouble,_please_block_its_IP_address._Thank_you."
The JSON readers
My JSON Feed had far fewer unique agents but a completely different audience. Unread and Syndicator together account for nearly 80% of all JSON feed traffic—yet they barely appear in the RSS logs. If you publish both formats, you might be reaching different tools and potentially different people. Maybe I should check-in on my Gopher site.
The JSON feed also attracted GPTBot, Shiori, and the Embarcadero Delphi client. But two apps seem to generally own the JSON feed, while the RSS feed is a cornucopia of crawlers and clients.
What did we learn?
RSS is inspiringly diverse! Way more diverse than browsers feel to me at least. Syndicating content on the web is and isn't as solved as you'd think. That there is this much variety gives me hope for something. In one week I saw over 50 distinct, identifiable products touching my feeds: commercial readers, self-hosted installations, newsletter bots, a podcast app, Fediverse instances from two different platforms, search engines from eight countries, AI crawlers from every major AI company, a prediction market, preservation services, email relays, bookmark managers, SEO crawlers, terminal readers, an Emacs package, and someone's Delphi app.
The self-hosted contingent is bigger than I thought. Miniflux, FreshRSS, CommaFeed, Bubo Reader, Newsboat, Elfeed—people running their own infrastructure to read feeds. Says something about the audience of a personal tech blog, maybe, but I think it also says something about the health of the self-hosted RSS ecosystem.
Everyone wants to read your feed, and not all of them are readers. Prediction markets. AI training pipelines. SEO crawlers. Newsletter ingestion bots. Link preview services. Bookmark archivers. The Internet Archive. RSS isn't just a reading protocol—it's infrastructure. A structured, machine-readable data feed with no authentication required that anything can consume. The human readers are almost certainly the minority, though I hope they exist somewhere at the end of these aggregation chains.
User agents are a beautiful mess. Between Elixir libraries, bare runtime strings, a UUID that should be an app name, fake browsers from 2011, a Nintendo Wii, a Sony Ericsson feature phone, a BeOS installation, someone's literal Python filename, and at least five agents I simply cannot identify, the user agent string remains the web's most charmingly unreliable metadata field. It's Knights and Knaves, but really mostly knaves.
Publishing both RSS and JSON feeds feels worth! They reach different audiences and are consumed by different tools. This was the most concrete takeaway—if I only had RSS, I wonder if I'd be invisible to Unread and Syndicator's users at all?
Full Reference Table
Most of the identifiable user agents I observed, linked to their source as best I could find it (some omitted at my discretion). Download as CSV.
| Name | Type | Description | Link |
|---|---|---|---|
| Feedly | RSS Reader | Cloud-based reader. Reports subscriber count in UA | feedly.com |
| Feedbin | RSS Reader | Hosted reader with sync. Reports subscribers and feed ID | feedbin.com |
| Feeder | RSS Reader | Browser-extension reader (Chrome, Firefox, Edge) | feeder.co |
| Inoreader | RSS Reader | Web-based reader with filtering and automation | inoreader.com |
| NetNewsWire | RSS Reader | Free, open-source Mac/iOS reader by Brent Simmons | netnewswire.com |
| Unread | RSS Reader | Beautiful iOS/Mac reader. Dominates JSON feed traffic | goldenhillsoftware.com/unread |
| feeeed | RSS Reader | iOS app mixing RSS with Reddit, YouTube, weather, and more | feeeed.nateparrott.com |
| AntennaPod | Podcast App | Open-source Android podcast manager | antennapod.org |
| Miniflux | Self-Hosted Reader | Minimalist self-hosted reader in Go | miniflux.app |
| FreshRSS | Self-Hosted Reader | PHP-based self-hosted RSS aggregator | freshrss.org |
| CommaFeed | Self-Hosted Reader | Java/React Google Reader replacement | github.com/Athou/commafeed |
| Bubo Reader | Self-Hosted Reader | Generates a static HTML page from your feed list | buboreader.com |
| Newsboat | Terminal Reader | Terminal-based reader for Linux/macOS | newsboat.org |
| Elfeed | Emacs Reader | Tag-based feed reader for Emacs | github.com/skeeto/elfeed |
| Syndicator | Reader/Aggregator | Personalized reading app that learns from behavior | app.syndicator.one |
| Feedstand | Reader | RSS reader service with feed IDs | feedstand.com |
| ReadYou | RSS Reader | Open-source Material Design reader for Android | github.com/Ashinch/ReadYou |
| SpaceCowboys | RSS Reader | Android RSS reader | play.google.com |
| BazQux | RSS Reader | Web-based reader. Reports subscriber count | bazqux.com |
| GoodLinks | Reading List | Bookmarking/reading-list app for Apple platforms | goodlinks.app |
| ReaderDesktop | RSS Reader | Native macOS RSS reader | readerdotone.app |
| Misskey | Fediverse | Decentralized Fediverse social platform | misskey-hub.net |
| Friendica | Fediverse | Facebook-like Fediverse platform | friendi.ca |
| Micro.blog | Fediverse/Platform | Indie microblogging platform's feed crawler | micro.blog |
| Content Platform | Digital magazine app's content proxy | flipboard.com | |
| Slackbot | Link Unfurling | Slack's preview bot. Fires when URLs are shared | api.slack.com/robots |
| Marginalia | Indie Search | One-person search engine for the small/personal web | marginalia.nu |
| Kagi | Indie Search | Paid, ad-free, privacy-focused search engine | kagi.com |
| rssanyway | Content Discovery | Generates feeds for sites without them. Ranks trending content | rssanyway.com |
| GeistHaus | Content Discovery | RSS meta-layer ranking articles by cross-feed links | geist.haus |
| GPTBot | AI Crawler | OpenAI's training data crawler | platform.openai.com/docs/bots |
| ChatGPT-User | AI Crawler | OpenAI's real-time browsing crawler | platform.openai.com/docs/bots |
| OAI-SearchBot | AI Crawler | OpenAI's SearchGPT crawler | platform.openai.com/docs/bots |
| ClaudeBot | AI Crawler | Anthropic's web crawler | docs.anthropic.com |
| PerplexityBot | AI Crawler | Perplexity's indexing crawler | perplexity.ai |
| Bytespider | AI Crawler | ByteDance/TikTok's web crawler | zhanzhang.toutiao.com |
| Applebot | AI/Search Crawler | Powers Siri, Spotlight, and Apple Intelligence | support.apple.com |
| Amazonbot | AI/Search Crawler | Feeds Alexa and the Rufus AI assistant | developer.amazon.com/amazonbot |
| Bravebot | Search Crawler | Brave Search's web crawler | search.brave.com |
| DuckDuckBot | Search Crawler | DuckDuckGo's search crawler | duckduckgo.com |
| DuckAssistBot | AI Crawler | DuckDuckGo's AI assistant crawler | duckduckgo.com |
| Polymarket-Bot | Prediction Market | Crypto prediction market's news scraper | polymarket.com |
| archive.org_bot | Preservation | Internet Archive's Wayback Machine crawler | archive.org |
| Shiori | Bookmarking | Self-hosted bookmark manager in Go (Pocket alternative) | github.com/go-shiori/shiori |
| Blogtrottr | Feed-to-Email | Delivers RSS to email inboxes | blogtrottr.com |
| FeedBurner | Feed Relay | Google's deprecated (but undead) feed proxy from 2007 | feedburner.google.com |
| WordPress.com Feedbot | Feed Relay | Automattic's crawler for WP.com Reader | wordpress.com |
| Kingfisher (TLDR) | Newsletter Bot | Feed ingestion for the TLDR Newsletter | github.com/tldrmedia/kingfisher |
| RSS.Social | Social Platform | Social platform built around RSS feeds | rss.social |
| Lighthouse | Curation App | RSS curation with AI summaries (not Google Lighthouse) | lighthouseapp.io |
| Hackney | Library (Elixir) | Elixir/Erlang HTTP client. Product unknown | github.com/benoitc/hackney |
| Apache HttpClient | Library (Java) | Java HTTP library. Product unknown | hc.apache.org |
| feedparser | Library (Python) | Canonical Python RSS parsing library | github.com/kurtmckee/feedparser |
| newspaper | Library (Python) | Python article extraction library | github.com/codelucas/newspaper |
| SimplePie | Library (PHP) | PHP feed parser. Powers WordPress's RSS widget | simplepie.org |
| rss-parser | Library (Node.js) | Popular npm package for parsing feeds | github.com/rbren/rss-parser |
| PicoFeed | Library (PHP) | PHP library originally built for Miniflux | github.com/miniflux/picoFeed |
| feed2exec | CLI Tool | Python CLI that runs commands on new feed items | feed2exec.readthedocs.io |
| Embarcadero URI Client | Runtime (Delphi) | Default UA from Delphi/RAD Studio apps | embarcadero.com |
| Deno | Runtime | Default UA from Deno's fetch() | deno.com |
| Bun | Runtime | Default UA from Bun JavaScript runtime | bun.sh |
| undici | Runtime (Node.js) | Default UA from Node.js 18+ native fetch() | github.com/nodejs/undici |
| node | Runtime (Node.js) | Bare Node.js string. No custom UA set | nodejs.org |
| AhrefsBot | SEO Crawler | One of the most active backlink crawlers | ahrefs.com/robot |
| MJ12bot | SEO Crawler | Majestic SEO's backlink crawler. Active since 2004 | mj12bot.com |
| DataForSeoBot | SEO Crawler | SEO data API for other companies' tools | dataforseo.com |
| SemrushBot | SEO Crawler | SEO analytics and competitive research | semrush.com |
| PetalBot | Search Crawler | Huawei's Petal Search engine crawler | webmaster.petalsearch.com |
| Qwantbot | Search Crawler | French privacy-focused search engine | help.qwant.com |
| SeznamBot | Search Crawler | Czech search engine Seznam.cz | o-seznam.cz |
| Smallwebindexbot | Indie Search | Search engine for the small web | smallwebindex.com |
| rawweb-bot | Indie Search | Search engine for independent personal websites and blogs | github.com/0x2E/RawWeb.org |
| YandoriRSSBot | News Monitoring | Monitors ~200K RSS feeds, clusters related articles | writeup by N.A. Ferrell |
| Uptime-Kuma | Monitoring | Open-source self-hosted uptime monitor | github.com/louislam/uptime-kuma |
| trafilatura | Library (Python) | Web text extraction for NLP/corpus building | github.com/adbar/trafilatura |
| colly | Library (Go) | Popular Go web scraping framework | github.com/gocolly/colly |
| Meta External Agent | Platform Crawler | Facebook/Instagram Open Graph preview crawler | developers.facebook.com |
If you enjoyed reading this consider sponsoring my work on GitHub or subscribing to my newsletter.
Share this post: Hacker News • Reddit • LinkedIn • Mastodon.
Published on Monday, May 18th 2026. Read this post as plain-text.